Field notes
The NeuroX Blog
What we learn shipping production AI — agents, RAG, growth automation, and the things AI prototypes get wrong.
 claude-codeai-agentsengineering
claude-codeai-agentsengineeringSpotify Auto-Merged 2.5 Million PRs. Then the Bottleneck Moved.
Spotify's fleet automation has merged more than 2.5 million maintenance pull requests, the vast majority with no human in the loop. The constraint is no longer writing code — it's deciding.
Jul 31, 2026Read mcpai-agentsproduction
mcpai-agentsproductionMCP Deleted Sessions — and 400M Monthly SDK Downloads Have to Follow
The 2026-07-28 spec removed the initialize handshake, the session ID, and stream resumability. Every MCP server you run against a stateful assumption is now on a migration clock.
Jul 30, 2026Read ai-agentssecurityengineering-discipline
ai-agentssecurityengineering-discipline66.5% of Malicious GitHub Issues Walked Past Every Agent Guardrail
A new benchmark hid malicious instructions inside ordinary-looking GitHub issues and pointed three production coding agents at them. Two-thirds got through — and the blocking that did happen came from the model, not the agent's safety layer.
Jul 29, 2026Read ai-agentsengineering-disciplineclaude-code
ai-agentsengineering-disciplineclaude-codeOrca Hit 31k Stars Running One Prompt Through Five Agents at Once
The trending orchestrator's core move isn't a better model — it's fanning one prompt across five agents in five isolated git worktrees and merging the winner. Which moves the bottleneck from generation to judgment.
Jul 28, 2026Read opus-5swe-benchai-agents
opus-5swe-benchai-agentsOpus 5 Hit 96% on SWE-bench Verified. Three Labs Are Now 1.1 Points Apart.
Claude Opus 5 launched July 24 and essentially saturated SWE-bench Verified at 96.0%. On the harder Pro variant, the top three flagship models from three different labs land within 1.1 points of each other. Model choice stopped being your coding differentiator.
Jul 27, 2026Read ai-agentsinfrastructuresecurity
ai-agentsinfrastructuresecurityCubeSandbox Hit 10k Stars Giving Each Agent Its Own 60ms Hardware Sandbox
Tencent Cloud open-sourced a microVM that boots a hardware-isolated sandbox in under 60ms with under 5MB overhead. The star count isn't the story. It makes per-task isolation cheap enough to be the default instead of a luxury.
Jul 24, 2026Read ai-agentsengineering-disciplinedesign
ai-agentsengineering-disciplinedesign15.8k Stars for a Skill That Stops Claude's UI Looking Like Claude's UI
Hallmark went viral by refusing the design every LLM defaults to — then running 57 gates to prove it did. The number developers are starring isn't a model. It's a taste checklist wired into the loop.
Jul 23, 2026Read token-efficiencycontext-engineeringai-agents
token-efficiencycontext-engineeringai-agents62% of Your Agent Bill Is Context You Already Sent
A 2026 cost breakdown of real agentic coding sessions found the single biggest line item wasn't the model's output — it was re-sending the same context every turn. One team cut $87k/month to $24k without slowing down.
Jul 22, 2026Read ai-agentsproductionclaude-code
ai-agentsproductionclaude-code7 Hours Alone in a 12.5M-Line Codebase. 99.9% Correct.
Rakuten had Claude Code implement a method inside vLLM in one unbroken autonomous run. The headline isn't the seven hours — it's the 99.9% accuracy against a reference, because that's the number autonomy usually can't produce.
Jul 21, 2026Read claude-codeagent-infrastructureproduction
claude-codeagent-infrastructureproductionClaude Code Just Got 79x Leaner. The Model Never Moved.
The July changelog shipped a 79x cut in transcript size and 7x faster tool rounds — with zero model upgrade. The gains came from the runtime, which is exactly where production lives.
Jul 20, 2026Read ai-agentssecurityevals
ai-agentssecurityevalsClaude Found 23,019 Vulnerabilities. The Only Number That Mattered Was 90.6%
Anthropic's Project Glasswing scanned 1,000+ open-source projects and surfaced 23,019 issues. Then six independent firms graded a sample — and that step, not the scan, is the one that turns agent output into something you can act on.
Jul 17, 2026Read ai-agentscomputer-usebenchmarks
ai-agentscomputer-usebenchmarksClaude's Computer Use Scores 83.5% — Then Drops to 20.6% on Real Work
A new benchmark stretched computer-use tasks from a few clicks to 1.6-hour workflows. The best model's completion rate collapsed by a factor of four. The gap is the whole story of production.
Jul 16, 2026Read ai-agentsevalsproduction
ai-agentsevalsproductionAnthropic's 'Outcomes' Lifted Quality 10% — By Adding a Grader, Not a Bigger Model
A new managed-agent feature raised generated-document quality by double digits with zero model upgrade. The gain came from one structural change: a second agent that grades the first against a rubric you wrote.
Jul 15, 2026Read ai-agentsproductiontesting
ai-agentsproductiontestingDoctolib Rebuilt Its Testing Infra in Hours, Not Weeks — and Ships 40% Faster
Anthropic's 2026 enterprise report has a case study most people read as a testing story. It's actually an infrastructure story: the agent's real win was replacing legacy test scaffolding, not writing tests.
Jul 14, 2026Read ai-agentsengineering-disciplineproduction
ai-agentsengineering-disciplineproduction77k Stars for a Repo That Just Stops Agents Taking the Shortcut
Addy Osmani's agent-skills isn't a model or a framework — it's 24 workflows that force a coding agent to write the spec, the test, and the security review it would otherwise skip. The star count is the market pricing in what actually separates a demo from production.
Jul 13, 2026Read ai-agentssecurityproduction
ai-agentssecurityproduction40k Stars for an AI Hacker That Won't Report a Bug It Can't Exploit
Strix went viral by inverting how security tools work: it runs your app, finds the hole, and proves it with a working exploit before it says a word. The design choice behind the stars is the one that separates a demo agent from a production one.
Jul 12, 2026Read ai-agentsproductionenterprise
ai-agentsproductionenterprise57% Ship Multi-Stage Agents. Only 16% Cross a Team Boundary.
Anthropic's 2026 enterprise survey shows most agents now handle multi-step work inside one team. The wall isn't building the agent — it's the jump to cross-functional, where integration and data access decide everything.
Jul 11, 2026Read claude-sonnet-5productionai-agents
claude-sonnet-5productionai-agentsSonnet 5 Is Now the Default. Swapping to It Isn't a One-Liner.
A mid-tier Sonnet just edged the flagship on knowledge work — and became the default overnight. But three silent default changes turn a model-string swap into a production incident nobody sees until load.
Jul 10, 2026Read ai-agentsclaude-coworkproduction
ai-agentsclaude-coworkproductionAnthropic's Cowork Data: Coding Is Just 8.7% of What Agents Do
The terminal was the beachhead, not the destination. Now the discipline that ships a coding agent has to follow it into finance, ops, and comms — where the failures are quieter.
Jul 9, 2026Read agentic-codinganthropicai-agents
agentic-codinganthropicai-agentsAnthropic's 2026 Report: AI Does 60% of the Work, Fully Delegated? 0–20%
Developers now use AI in most of their work — but the share they can actually hand off unattended is tiny. The gap between those two numbers is where production lives.
Jul 8, 2026Read claude-codeopenai-codexai-agents
claude-codeopenai-codexai-agentsOpenAI Just Shipped a Plugin for Claude Code — 25.8k Stars
OpenAI's official Codex plugin runs inside its competitor's harness and now tops GitHub trending. When your rival ships to your terminal, the terminal has become the platform.
Jul 6, 2026Read claude-sonnet-5ai-agentstoken-cost
claude-sonnet-5ai-agentstoken-costClaude Sonnet 5 Ships at $2/$10 — and Runs Agents Like Opus
Anthropic just made near-Opus agentic capability the default at 60% below Opus pricing. Cheaper tokens are a real lever — but only if your pipeline isn't quietly multiplying them.
Jul 3, 2026Read ai-productivitydeveloper-productivityengineering-discipline
ai-productivitydeveloper-productivityengineering-discipline93% of Developers Use AI. Productivity Moved 10%.
Adoption is near-total; the measured payoff is a rounding error. The gap isn't a tooling problem — it's arithmetic, and it lands squarely on the part a demo skips.
Jul 1, 2026Read terminal-benchai-agentsclaude-code
terminal-benchai-agentsclaude-codeSame Model, Two Harnesses, a 3-Point Swing on Terminal-Bench
Terminal-Bench 2.1 scores the agent and the model as a pair — and the same Fable 5 moves three points depending on which harness wraps it. The leaderboard you're reading measures the wrong thing.
Jun 30, 2026Read mcptoken-efficiencyai-agents
mcptoken-efficiencyai-agentsThe Same Task Cost 44,026 Tokens on MCP — and 1,365 on a CLI
A benchmark ran one trivial query two ways. The MCP agent burned 32x more tokens than the CLI agent, and almost all of it was schema the model never used. The bill for that gap shows up only in production.
Jun 29, 2026Read ai-agentsenterpriseroi
ai-agentsenterpriseroi80% of Enterprises Now Say Their AI Agents Pay for Themselves
Anthropic's 2026 enterprise survey lands a number the failure stories missed: agent investments are returning measurable economic value at scale. The interesting part is which workflows got there — and which still haven't.
Jun 26, 2026Read prompt-cachingai-agentsengineering-discipline
prompt-cachingai-agentsengineering-disciplineGitHub Watches One Number on Its Claude Agents: 94% Cache Hit Rate
GitHub's chief product officer says prompt cache hit rate is the foundational metric for any team at scale — and a drop to 70% means a bug, not a slow day. The interesting part is what they monitor isn't the model.
Jun 25, 2026Read code-reviewai-agentsengineering-discipline
code-reviewai-agentsengineering-disciplineAI Merged 98% More PRs. Review Time Went Up 91%.
Faros.ai measured high-AI-adoption teams and found the speed didn't disappear — it moved. Code got written faster and piled up at the one stage nobody automated: human review.
Jun 24, 2026Read context-engineeringai-agentsclaude-code
context-engineeringai-agentsclaude-codeThey Shrank the Context Window. Bug-Fix Accuracy Jumped 13 Points.
A team switched from a 2M-token model to a 64k window with retrieval — and got more accurate, not less. Bigger context stopped helping a while ago, and most production agents are paying for tokens they can't actually use.
Jun 23, 2026Read agentic-codingai-agentsproductivity
agentic-codingai-agentsproductivity27% of AI Coding Work Wouldn't Have Happened Without Agents
Anthropic's 2026 report measures the part of agent value everyone misprices: not faster work, but work that was never viable before. The ROI question you're asking is the wrong one.
Jun 22, 2026Read ai-code-qualityprototype-to-productionai-agents
ai-code-qualityprototype-to-productionai-agents94% Say AI Code Looks Better. 82% Shipped a Production Failure From It.
New Relic surveyed 200 enterprise tech leaders: AI-generated code grades higher in review and breaks more in production. The gap between those two numbers is exactly where the work is.
Jun 21, 2026Read mcpai-agentstoken-economics
mcpai-agentstoken-economicsCodebase-Memory: 99% Fewer Tokens by Letting Agents Read a Graph, Not grep
A trending MCP server indexes your repo into a knowledge graph and answers structural questions with 99.2% fewer tokens than file-by-file exploration. The lesson isn't the tool — it's that brute-force context is a cost bug.
Jun 19, 2026Read anthropicai-agentsproduction
anthropicai-agentsproductionFable 5 Went Offline 3 Days After Launch — for Everyone
Anthropic's most capable model shipped June 9 and was pulled June 12 by a US export directive — offline for all users, not just foreign ones. If your agent is hard-wired to one model, you just saw your risk.
Jun 18, 2026Read enterprise-aiai-agentsprototype-to-production
enterprise-aiai-agentsprototype-to-production86% Now Ship Agents to Production — and 46% Hit the Same Wall
Anthropic's 2026 enterprise survey says 86% of organizations now deploy agents for production code. The same survey names the thing stopping the rest: integration, not intelligence.
Jun 17, 2026Read ai-agentsprototype-to-productionbenchmarks
ai-agentsprototype-to-productionbenchmarksAgents Just Hit 66% — and 89% Still Never Ship
The 2026 Stanford AI Index shows agents leapt from 12% to 66% on OSWorld in a single year, within 6 points of human performance. Capability isn't the blocker anymore. 89% of enterprise agents still never reach production.
Jun 16, 2026Read swe-benchai-agentsproduction-reliability
swe-benchai-agentsproduction-reliabilityBoth Top Models Tied at 88.6% — Then the Harder Benchmark Failed a Third of the Time
On SWE-bench Verified, Opus 4.8 and GPT-5.5 are now in a dead heat at ~88.6%. On SWE-bench Pro — the messier, multi-file version — the leader scores 69.2%. The benchmark that saturated tells you nothing; the one that didn't tells you where your agent breaks.
Jun 16, 2026Read ai-agentsorchestrationprototype-to-production
ai-agentsorchestrationprototype-to-productionEnterprises Now Run 12 AI Agents. Half of Them Work Alone.
A new 2026 report puts the average enterprise at 12 deployed agents — but half operate in complete isolation, and only 11% of last year's planned agent projects ever reached production. The gap isn't the model. It's orchestration.
Jun 15, 2026Read mcpai-agentssupply-chain
mcpai-agentssupply-chainYour Agent's MCP Config Is a Supply-Chain Blind Spot. Perplexity Just Shipped the Scanner
Bumblebee reads the messy local state every other tool ignores — including the MCP configs that feed your AI agents. It crossed 4,400 GitHub stars in three weeks because almost nothing else looks there.
Jun 13, 2026Read claude-codeengineering-disciplineai-agents
claude-codeengineering-disciplineai-agentsA 70-Line File Just Passed 220,000 GitHub Stars
It contains no code — just four rules for how an AI agent should behave. That it's now one of the most-starred repos on GitHub tells you exactly where the bottleneck moved.
Jun 12, 2026Read claude-codeagent-sdkcost-optimization
claude-codeagent-sdkcost-optimizationOn June 15, Your Automated Agents Stop Being Free
Anthropic is splitting programmatic Claude usage into a separate, metered credit pool. The CI agent that ran for free on your subscription now bills at API list price — and the credit doesn't roll over.
Jun 11, 2026Read anthropicclaude-codeai-agents
anthropicclaude-codeai-agentsAI's Task Horizon Now Doubles Every 4 Months — Down From 7
The cadence of progress is itself accelerating: the time an AI can work autonomously is doubling every 4 months instead of 7. The reason is uncomfortable — Claude is now building Claude.
Jun 10, 2026Read claude-codeai-agentsproduction
claude-codeai-agentsproduction67% vs 25%: The Coding-Agent Gap GitHub Stars Don't Show
June 2026's dev-tool rankings show the coding-agent field is crowded and cheap. But in blind reviews, engineers preferred Claude Code's output 67% of the time and Codex's 25%. Adoption metrics measure hype. They don't measure what ships.
Jun 9, 2026Read anthropicclaude-codeai-agents
anthropicclaude-codeai-agentsOpus 4.6 Runs Unsupervised for 14.5 Hours — Half of Those Runs Fail
Claude Opus 4.6 now sustains autonomous work for 14.5 hours before its success rate drops to a coin flip. No competitor has published a comparable number. That ceiling is real — and so is the discipline it demands.
Jun 8, 2026Read ai-agentsagentic-codingproduction
ai-agentsagentic-codingproductionOpenClaw: 100 Agents, $1.3M in Tokens, 30 Days
The fastest-growing open-source project in GitHub history was built by ~100 AI agents running in parallel — at a $1.3M monthly token bill. The viral story hides the real lesson: orchestration and cost discipline, not raw model speed.
Jun 6, 2026Read anthropicclaude-codeai-agents
anthropicclaude-codeai-agents80% of Anthropic's Production Code Is Now Written by Claude
In May 2026, most code merged at Anthropic was AI-authored, not human. The surprise isn't the volume — it's what didn't change: every line still ships through review, tests, and a merge gate.
Jun 5, 2026Read ai-agentsproductionanthropic
ai-agentsproductionanthropic5 Hours to 7 Minutes: What Real Agent Deployments Look Like in 2026
eSentire just compressed threat analysis from 5 hours to 7 minutes with 95% alignment to senior experts. Across 500+ technical leaders, 80% report measurable economic returns. The pattern is clear — and repeatable.
Jun 4, 2026Read anthropicai-agentsproduction
anthropicai-agentsproductionSWE-bench 87%: The Score That Made Infrastructure the New Bottleneck
Opus 4.7 hit 87% on SWE-bench Verified — up from 62% a year ago. Anthropic's Code with Claude 2026 event didn't celebrate the benchmark. It shipped managed infrastructure, because that's where the work actually stalls.
Jun 3, 2026Read claude-codeai-agentsanthropic
claude-codeai-agentsanthropicClaude Code Now Writes Its Own Agent Orchestration
Dynamic Workflows just shipped in research preview — Claude generates its own orchestration scripts on the fly, runs subtasks in parallel, and verifies results before surfacing them. 86% of teams were already running agents in production when this landed.
Jun 2, 2026Read ai-agentsproductionengineering
ai-agentsproductionengineering22,900 Stars: The 12-Factor Checklist Every Agent Team Is Saving
Humanlayer's 12-factor-agents reached 22.9k GitHub stars by naming what production teams already know: 80% quality with a framework is easy. The last 20% — customer-facing, on-call-worthy — requires owning your prompts, your context window, and your control flow.
May 31, 2026Read claude-agentsanthropicproduction
claude-agentsanthropicproductionNetflix Is Already Running Claude's New Multiagent Orchestration
Anthropic shipped Dreaming, Outcomes, and Multiagent Orchestration to Claude Managed Agents this week. Netflix deployed the orchestration feature on its platform team before the ink was dry.
May 29, 2026Read ai-agentsproductiongithub
ai-agentsproductiongithub73,000 New GitHub Stars in 7 Days Point to One Gap
The week of May 21, GitHub's top-10 trending repos added 73,000 stars — and 9 of 10 shared a single focus: infrastructure for running agents in production. The experimentation phase is over.
May 26, 2026Read- ai-agentsmodel-routingtoken-efficiency
31.5k Stars for a Router: Model Choice Is Now a Runtime Decision
OmniRoute crossed 31.5k GitHub stars putting one endpoint in front of 500+ models. The free-token pitch is the headline. The real shift is that picking a model stopped being an architecture decision and became a per-task one.
May 24, 2026Read  claude-codeai-agentsengineering
claude-codeai-agentsengineeringCode with Claude 2026: Half of Devs Ship PRs They Never Read
At Anthropic's May event, nearly 50% of attendees reported shipping Claude-written pull requests without reading the code first. SWE-bench is at 87%. The model is no longer the bottleneck — discipline is.
May 23, 2026Read- ai-agentsengineering-disciplinedocumentation
OpenWiki Hit 13k Stars Making Docs an Artifact Your Agents Maintain
LangChain's new CLI writes an agent-readable wiki for your repo — then keeps it in sync with scheduled PRs. The star count isn't the story. Stale docs don't just slow humans; they confidently mislead the agent.
May 23, 2026Read  claude-codeai-agentsenterprise
claude-codeai-agentsenterpriseMCP Tunnels Ship: Your Agent Can Now Reach Internal Systems Without a Public Endpoint
Anthropic just shipped MCP tunnels and self-hosted sandboxes for Claude Managed Agents. For the first time, an agent can reach your internal Postgres, private APIs, and ticketing systems through a single encrypted outbound connection — no inbound firewall rules, no data leaving your perimeter.
May 22, 2026Read ai-agentsanthropicai-engineering
ai-agentsanthropicai-engineeringKarpathy Called Agents Slop. Now He's Running 700 Overnight at Anthropic.
Andrej Karpathy publicly called agentic output 'slop' in October 2025. This week he joined Anthropic to build overnight research loops that run 700 experiments per two-day run — and logged an 11% training speedup. The critique wasn't wrong. The scaffolding was.
May 21, 2026Read claude-codeai-agentsproduction
claude-codeai-agentsproductionMercado Libre Is Betting 23,000 Engineers on 90% Autonomous Coding by Q3
At Code w/ Claude 2026, Anthropic put a number on the next phase: Mercado Libre is targeting 90% autonomous coding across 23,000 engineers by Q3. The new Routines feature is the primitive that makes it sane.
May 20, 2026Read ai-agentsproductionai-engineering
ai-agentsproductionai-engineering46% of AI Teams Say Integration Is the Bottleneck. Not the Model.
The 2026 State of AI Agents survey ranked the top three reasons agents stall in production. None of them are model capability. 46% point at integration, 42% at data, 40% at security. The wiring is the work.
May 19, 2026Read claude-opusai-agentsproduction
claude-opusai-agentsproductionOpus 4.7 Hit 64.3% on SWE-bench Pro. The Real Story Is a Third of the Tool Errors.
Everyone quoted the +10.9 SWE-bench Pro jump when Anthropic shipped Opus 4.7. The number production teams should care about is buried two paragraphs in: a third of the tool errors compared to Opus 4.6. Tool errors are the production failure mode.
May 18, 2026Read- claude-opus-4-8ai-agentsproduction-reliability
Anthropic Shipped the Best Coding Model — Then Published 5 Transcripts of It Failing
Opus 4.8 tops SWE-bench at 88.6% and now writes about 10% of public GitHub commits. The most useful page in its system card is the one where Anthropic shows it failing at ordinary work — always the same way.
May 16, 2026Read - anthropicclaude-codeai-agents
Claude Fable 5 Hits 80% on SWE-bench Pro — and Wants to Run for Days
Anthropic shipped Fable 5 on June 9, jumping SWE-bench Pro from 69% to 80% and built explicitly for multi-day autonomous sessions. The model crossed a line. Most pipelines haven't.
May 16, 2026Read  ai-agentsproductioncase-studies
ai-agentsproductioncase-studiesFrom 5 Hours to 7 Minutes: What AI in Production Actually Looks Like in 2026
Anthropic's 2026 enterprise report dropped four shipping case studies with real numbers — eSentire, Doctolib, L'Oréal, Thomson Reuters. None are pilots. All are the wiring around the model, not the model.
May 5, 2026Read claude-codeai-agentsanthropic
claude-codeai-agentsanthropicClaude Managed Agents Just Killed the 3-Month Setup Tax on Production AI
Anthropic shipped Managed Agents to public beta on April 8, removing the sandbox / state / credential plumbing every team used to spend a quarter building. Runtime is $0.08/hour. The interesting question is what teams build with that quarter back.
May 4, 2026Read claude-codeai-agentsengineering
claude-codeai-agentsengineeringAnthropic's 2026 Agentic Coding Report: 60% AI Usage, But Only 0–20% Fully Delegated
The new Agentic Coding Trends Report names the gap most teams are still pretending isn't there: AI writes most of the code, humans still own the last mile. The teams winning have stopped trying to remove engineers and started orchestrating them.
May 1, 2026Read case-studyprototype-to-productionfintech
case-studyprototype-to-productionfintechCase Study: From Broken AI Prototype to Production Fintech in 6 Weeks
A Series A fintech with a Bolt-built MVP couldn't onboard their first paying enterprise customer. Here's what was broken under the hood — and what we shipped to fix it.
Apr 30, 2026Read claude-codeskillsai-engineering
claude-codeskillsai-engineeringmattpocock/skills Just Hit #2 on GitHub Trending: Engineering Discipline as a Claude Skill
Matt Pocock open-sourced his personal .claude directory and it picked up 7,000+ stars in a day. The skills aren't about generating code faster — they're about not breaking the codebase while you do.
Apr 30, 2026Read uitoolingclaude-code
uitoolingclaude-codeThe 2026 Stack for AI-Assisted UI: 21st.dev + UI/UX Pro Max + Motion
Three tools that turn 'I need a marketing site' into 'this is live by Friday.' Here's the stack we use, and how each piece slots in.
Apr 29, 2026Read prototype-to-productionnext.jsvibe-coding
prototype-to-productionnext.jsvibe-codingFrom Bolt to Production: What AI Prototypes Get Wrong
30 minutes in, you have a working app. Auth, dashboard, even a Stripe modal. It looks done. It's not. Here's the punch list of what's actually broken under the hood.
Apr 29, 2026Read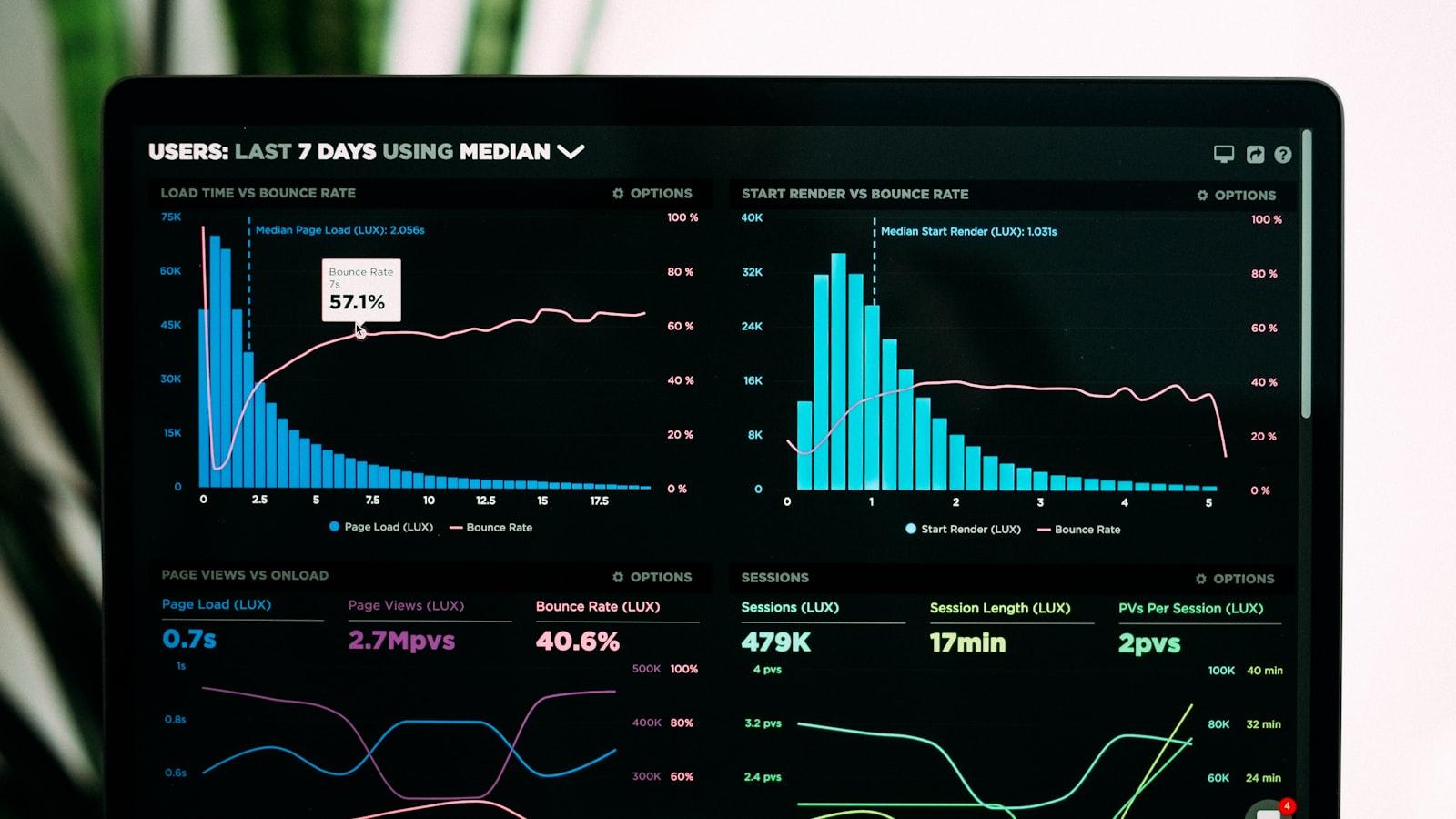 aeogrowth-marketingseo
aeogrowth-marketingseoAnswer Engine Optimization: How to Get Cited by ChatGPT, Perplexity, and Claude
In 2026, half your buyers ask ChatGPT instead of Google — and never click through. If you're not in the answer, you didn't lose a click. You lost the conversation.
Apr 28, 2026Read ai-agentspricingcost-optimization
ai-agentspricingcost-optimizationWhat an AI Agent Actually Costs to Build and Run
Most AI agency quotes hide three big costs. Build, inference, operate — here's the honest breakdown of what you'll pay in year one and what's missing from the quote.
Apr 27, 2026Read
Contact
Send us a brief.
Tell us about the problem in 2-3 sentences. We reply within one business day.
Or skip the form — book a Calendly slot directlyadmin@neuroxai.com · +91 70149 99768
Remote-first team across India · US · EU · HQ in Udaipur, India